
Development of valuable predictive read-across models based on “real-life” (sparse) nanotoxicity data†

Abstract
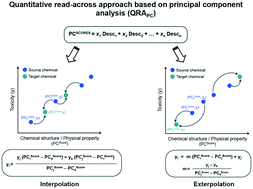
In view of the rapidly growing number of synthesized nanoparticles as well as public concerns about their potential negative impacts on human health and the environment, there is an urgent need to address current risk assessment data gaps. Thus, the development of comprehensive computational methods (e.g., read-across methods) for filling data gaps that meet realistic data needs is crucial. The present study proposes a new quantitative read-across approach based on linear algebra (i.e., one/two-point-slope formula) and one of the most widely used unsupervised pattern recognition methods (i.e., principal component analysis). The applicability and usefulness of the newly developed read-across algorithm for pre-screening hazard assessment of nanomaterials are confirmed by using three literature nanotoxicity datasets. The findings from this study clearly indicate that the proposed read-across approach provides reasonably accurate and statistically significant results of estimations of nanotoxicity data. Therefore, the method can be used for prioritizing current and future nanoparticles for the purpose of further testing and risk assessment.
 Please wait while we load your content...
Please wait while we load your content...

