
Common mistakes in cross-validating classification models†

Abstract
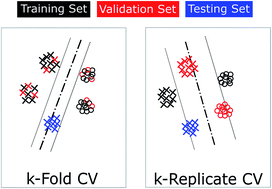
The common mistakes of cross-validation (CV) for the development of chemometric models for Raman based biological applications were investigated. We focused on two common mistakes: the first mistake occurs when splitting the dataset into training and validation datasets improperly; and the second mistake is regarding the wrong position of a dimension reduction procedure with respect to the CV loop. For the first mistake, we split the dataset either randomly or each technical replicate was used as one fold of the CV and we compared the results. To check the second mistake, we employed two dimension reduction methods including principal component analysis (PCA) and partial least squares regression (PLS). These dimension reduction models were constructed either once for the whole training data outside the CV loop or rebuilt inside the CV loop for each iteration. We based our study on a benchmark dataset of Raman spectra of three cell types, which included nine technical replicates respectively. Two binary classification models were constructed with a two-layer CV. For the external CV, each replicate was used once as the independent testing dataset. The other replicates were used for the internal CV, where different methods of data splitting and different positions of the dimension reduction were studied. The conclusions include two points. The first point is related to the reliability of the model evaluation by the internal CV, illustrated by the differences between the testing accuracies from the external CV and the validation accuracies from the internal CV. It was demonstrated that the dataset should be split at the highest hierarchical level, which means the biological/technical replicate in this manuscript. Meanwhile, the dimension reduction should be redone for each iteration of the internal CV loop. The second point is the optimization of the performance of the internal CV, benchmarked by the prediction accuracy of the optimized model on the testing dataset. Comparable results were observed for different methods of data splitting and positions of dimension reduction in the internal CV. This means if the internal CV is used for optimizing the model parameters, the two mistakes are less influential in contrast to the model evaluation.
 Please wait while we load your content...
Please wait while we load your content...

