
 : a Python framework for assessing similarity in materials-science data
: a Python framework for assessing similarity in materials-science data


Abstract
Computational materials science produces large quantities of data, both in terms of high-throughput calculations and individual studies. Extracting knowledge from this large and heterogeneous pool of data is challenging due to the wide variety of computational methods and approximations, resulting in significant veracity in the sheer amount of available data. One way of dealing with the problem is using similarity measures to group data, but also to understand where possible differences may come from. Here, we present 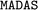 , a Python framework for computing similarity relations between material properties. It can be used to automate the download of data from various sources, compute descriptors and similarities between materials, analyze the relationship between materials through their properties, and can incorporate a variety of existing machine learning methods. We explain the architecture of the package and demonstrate its power with representative examples.
, a Python framework for computing similarity relations between material properties. It can be used to automate the download of data from various sources, compute descriptors and similarities between materials, analyze the relationship between materials through their properties, and can incorporate a variety of existing machine learning methods. We explain the architecture of the package and demonstrate its power with representative examples.

 Please wait while we load your content...
Please wait while we load your content...
 : a Python framework for assessing similarity in materials-science data
: a Python framework for assessing similarity in materials-science data

