
Analysis of omics data with genome-scale models of metabolism
Abstract
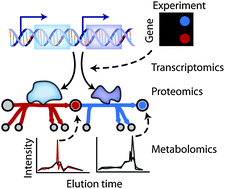
Over the past decade a massive amount of research has been dedicated to generating omics data to gain insight into a variety of biological phenomena, including cancer, obesity, biofuel production, and infection. Although most of these omics data are available publicly, there is a growing concern that much of these data sit in databases without being used or fully analyzed. Statistical inference methods have been widely applied to gain insight into which genes may influence the activities of others in a given omics data set, however, they do not provide information on the underlying mechanisms or whether the interactions are direct or distal. Biochemically, genetically, and genomically consistent knowledge bases are increasingly being used to extract deeper biological knowledge and understanding from these data sets than possible by inferential methods. This improvement is largely due to knowledge bases providing a validated biological context for interpreting the data.
 Please wait while we load your content...
Please wait while we load your content...