
Chemical documents: machine understanding and automated information extraction†
Abstract
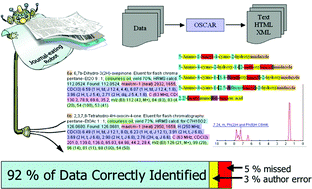
Automatically extracting chemical information from documents is a challenging task, but an essential one for dealing with the vast quantity of data that is available. The task is least difficult for structured documents, such as chemistry department web pages or the output of computational chemistry programs, but requires increasingly sophisticated approaches for less structured documents, such as chemical papers. The identification of key units of information, such as chemical names, makes the extraction of useful information from unstructured documents possible.
 Please wait while we load your content...
Please wait while we load your content...

